
Recently I had to battle a new issue with the quite-new Oracle Database RAC Version 12.2.0.1 on Linux x86_64. The idea of RAC is, to compensate the loss of a node or service by restarting services on other nodes. But in my case, when one node in a two-node-Cluster was down (or the crs stack stopped with crsctl stop crs), there was very high CPU load on the surviving node. In a pattern of three minutes 100% on four threads, every five minutes. That’s a bit disappointing – if we loose a node, we want all the CPU power of the survivor for our services, not for debugging, as interesting the debug results may be afterwards – but the service must stay up!
Oracle RAC 12.2 High Load on CPU from GDB when Node Missing
So where does that load come from? A quick research with top allows some insight: There are several GDB processes running.
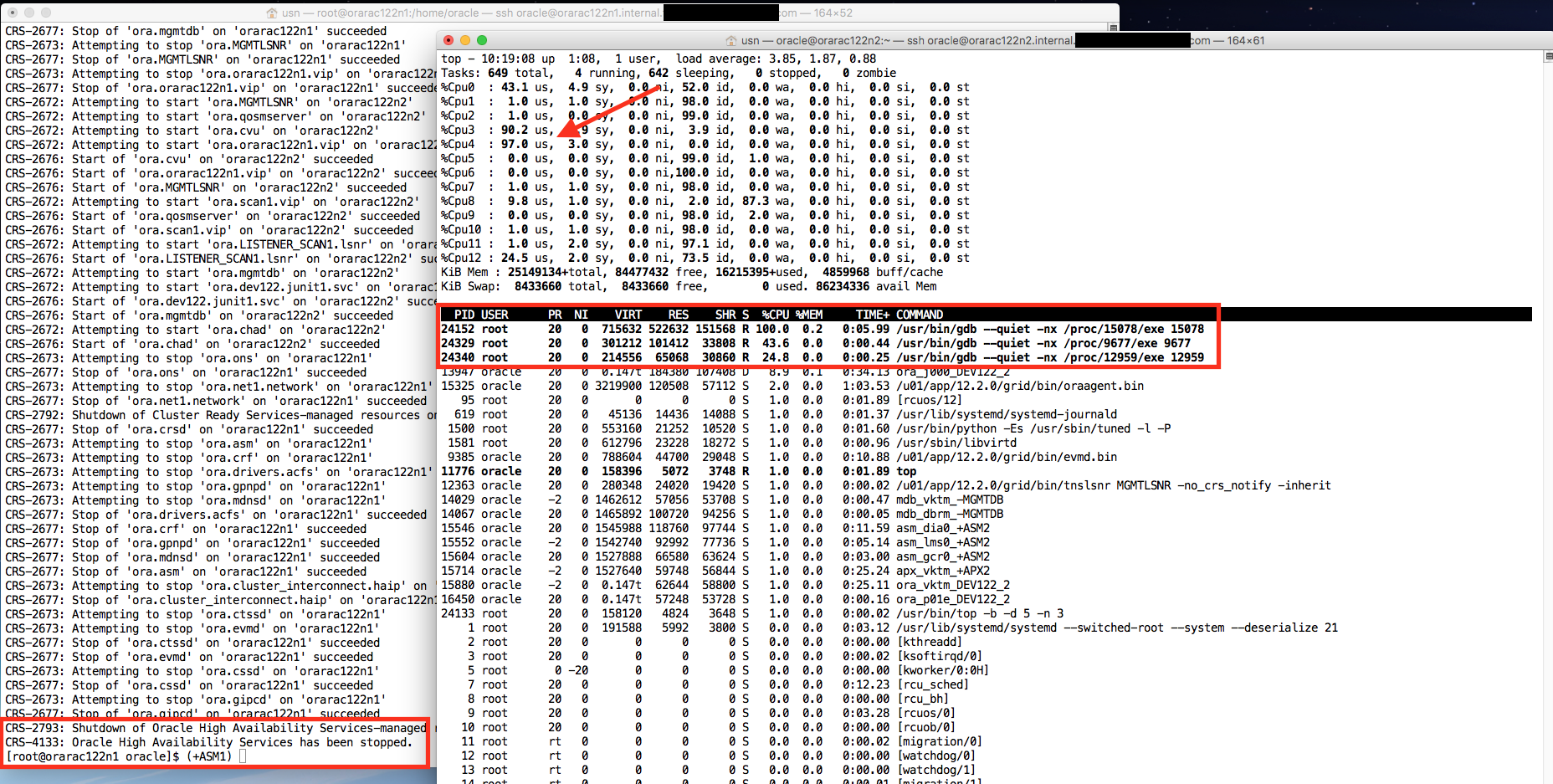
Digging deeper with pstree, shows their origin.
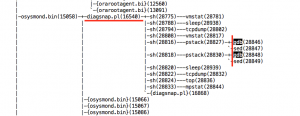
Seems like osysmond starts diagsnap.pl due to an error condition. And likewise, diagsnap is running the debugger. Okay, once or twice would be ok, but up to six gdb’s at the same time as in our case, and every five minutes – thanks, but no thanks.
Diagsnap is used by the Oracle 12.2 Autonomous Health Framework to create diagnostics information in case of cluster issues. Mostly that means data for the management repository database.
I was able to reproduce the issue on all Linux RACs with 12.2 I have running, also verified with at least two customer systems.
Workaround
The Cluster Health Monitor can be configured not to collect this kind of information – you will reduce the amount of data Oracle Support can use to help you diagnosing cluster outages. But on the pro side, you will have the CPU power of the surviving node for your services, and that was the plan.
Activate all nodes in the cluster, and on one node, run
~$ oclumon manage -disable diagsnap Here we go:

After that, I was not able to reproduce the issue.
Solution
Oracle told me, that a real fix will be part of the first 12.2 PSU, so I estimate to see it working after July 17th, 2017.
Readme
You may not be familiar with Cluster Health Monitor and the oclumon CLI. This is a good point for starting to read about the topic:
https://docs.oracle.com/database/121/CWADD/troubleshoot.htm#CWADD92242
Hope this is helpful – do it like we did and test thoroughly before commissioning your new RAC! 🙂
Martin Klier
Thanks a lot 😊
sorry … link no more valid 🙁
could you please provide any alternative link
Also ..
Q1. if we disable diagsnap , is there any impact or going to miss any import data/black box during cluster crash ??