
Oracle has released its new database version 12.1.0.2 that includes the famous in-memory column store. InMemory option promises a big advantage for OLAP-like work loads by keeping table contents in a columnar in-memory structure. InMemory is not new, they did that for decades, but the interesting part is “columnar”. There’s much writing about that on the net and in the Oracle Concepts Guide, no need to reproduce that here.
But though the new feature is very young, we already can see a “you can stop using your brain, we have a new catch-them-all feature” thinking, at least such a marketing sound. But it’s quite easy to show that this is not real. As for many other features we got over the years, using Oracle InMemory still needs a concept, done by an architect knowing the ups and downs.
What I can see from playing with Oracle Inmemory is, that it’s only beneficial when all data you (might) have to query from is already in the columnar cache (Oracle term is “populated”). If not, query response times don’t improve much. Let me show you my test case.
Testing environment facts:
- Oracle Database 12.1.0.2 on Linux 64bit (OEL 6.5)
- 4 CPUs
- SGA: 3GB, no automatic memory management, but dynamic buffer cache/shared pool
- Table BIGTHING with 46.5 millon rows / 6,1GB (Parallel 2)
- Table SMALLTHING with 5.6 millon rows / 768MB (Parallel 2)
- Both tables stem from DBA_OBJECTS
- no indexes or constraints
- HERE is my test script
The test query joins them by OBJECT_ID, and limits res result with SMALLTHING.OBJECT_ID<100. In a conventional Oracle system, this results in two full table scans and a fat hash join. With InMemory option, we get this execution plan with TABLE ACCESS (INMEMORY FULL). This is expected, and does not change all over my test:
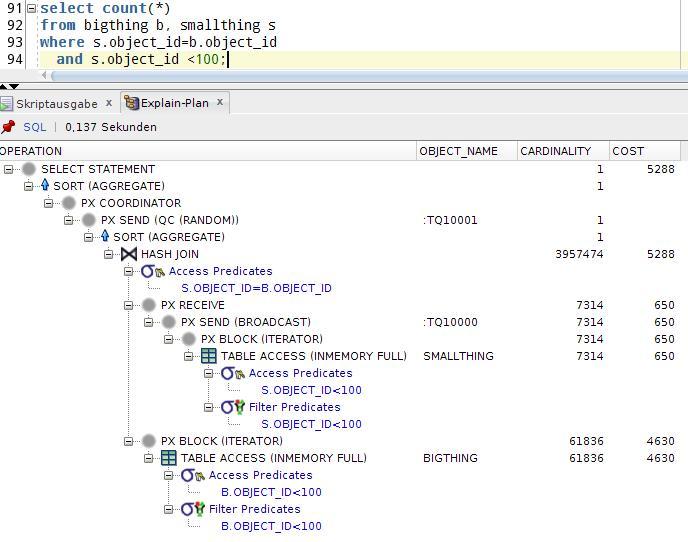
If I plainly configure both tables for INMEMORY, they have an inmemory size from v$IM_SEGMENTS of more than 800MB. To simulate limited resources, my INMEMORY_SIZE parameter is 400M.
alter table bigthing NO INMEMORY;
alter table smallthing NO INMEMORY;
Here are my execution time averages:
- My baseline, the conventional plan ( TABLE ACCESS FULL): 13s
- Executing the SQL to trigger population: 17s
- Executing the SQL while the population is still underway: 24s
- Population is done, but still 400MB of BIGTHING not populated due to limited INMEMORY size: 12s
- => Not really faster
But when I think about the schema and the query, I come to the conclusion, that I only need one column per table in the columnar cache, and thus, all should fit in. Column OBJECT_ID will do, anything else is opted out!
alter table bigthing inmemory PRIORITY CRITICAL no inmemory (OWNER,…,ORACLE_MAINTAINED);
alter table smallthing inmemory PRIORITY CRITICAL no inmemory (OWNER,…,ORACLE_MAINTAINED);
- My baseline, the conventional plan ( TABLE ACCESS FULL): 13s
- Executing the SQL to trigger population: 27s
- Executing the SQL while the population is still underway: 25s
- Population is done, but still 400MB of BIGTHING not populated due to limited INMEMORY size: 0.35s
- Wow! 13s to 0.35s, that’s 37 times faster.
Another test, with slightly less INMEMORY_SIZE than needed (1GB, so 10% not populated) resulted in 0.85s query time. Compared with 13s, that’s great, but with an optimal design you still can improve this number by factor 2 or maybe 3.
My conclusion of today is: As long as you don’t have as much RAM as you have segment size, you need to know what your SQLs will look like and how they will behave. From that knowledge, you can derive your instance- and schema-side INMEMORY configuration, and from nothing else.
Stay wide awake
Martin Klier